

Research Interests

My name is Mathieu Guillame-Bert, and I am working in Google Zurich, Switzerland.
I did my Postdoctoral at CMU (Carnegie Mellon University) in the Auton-Lab (part of Robotic Institute) under the supervision of Artur Dubrawski. I studied the use of rule extraction and decision forest-like techniques for symbolic and numerical time series. Typical applications include Automated and/or assisted Medical Diagnostics, Medical Forecasting, Human Activity Recognition and Forecasting, Banking Activity Patterns, Fault Detection and Prediction on complex systems, automatic Foreign exchange market trading, and a bit of Robotics.
I defended my PhD in France in 2012 at the INRIA Research Lab in the PRIMA team under the supervision of James L. Crowley. I studied the automated extraction of patterns from large temporal datasets, as well as the use of those models for automated prediction, user interpretation and automated reasoning.
I graduate from the Master of Advance Computing of the Imperial College of London, and from the "French Grande Ecole" ENSIMAG (Ecole Nationale Supérieure d'Informatique et de Mathématiques Appliquées) in 2009.

Publications
2022
Article
2020
Article
2018
Article
2017
Journals/Conference Proceedings
2016
Journals/Conference Proceedings
Tutorial
Article
2015
Presentation
2014
Workshop
Presentation
2013
Presentation
Tutorial
2012
Journals/Conference Proceedings
Report
Committee: Pr. Malik Gha llab, Pr. Paul Lukowicz, Dr. Artur Dubrawski, Pr. Augustin Lux
Presentation
2011
Journals/Conference Proceedings
2010
Journals/Conference Proceedings
Prior to 2010
Report
Distinguished MSc project [page]
Curriculum vitae

Softwares & Datasets
Softwares
Github page, TensorFlow.org page.
Github page.

Part of the MGB Framework.
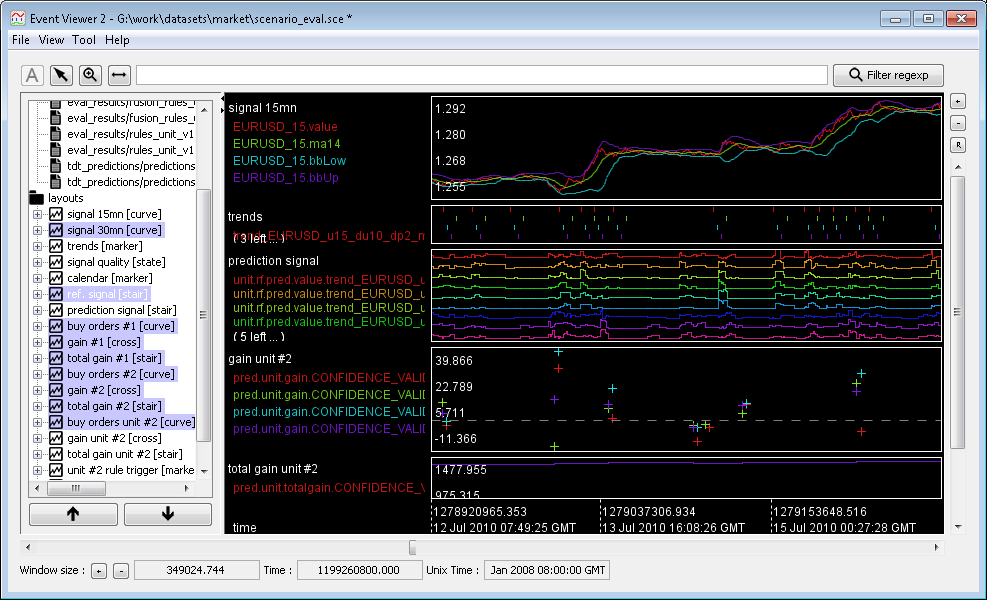
Part of the MGB Framework.
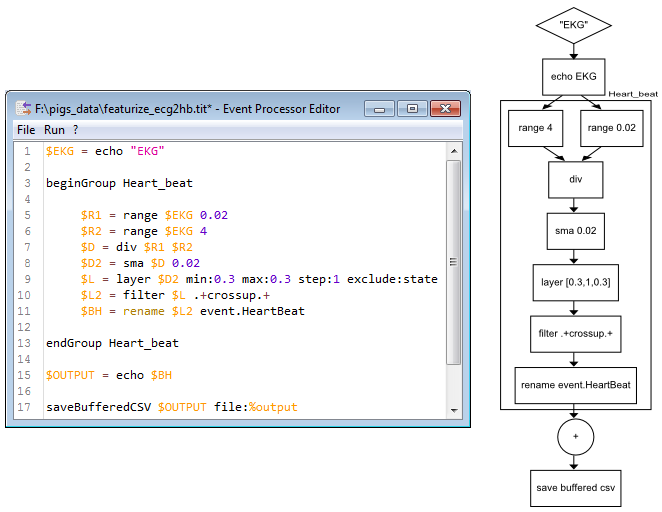
Part of the MGB Framework.
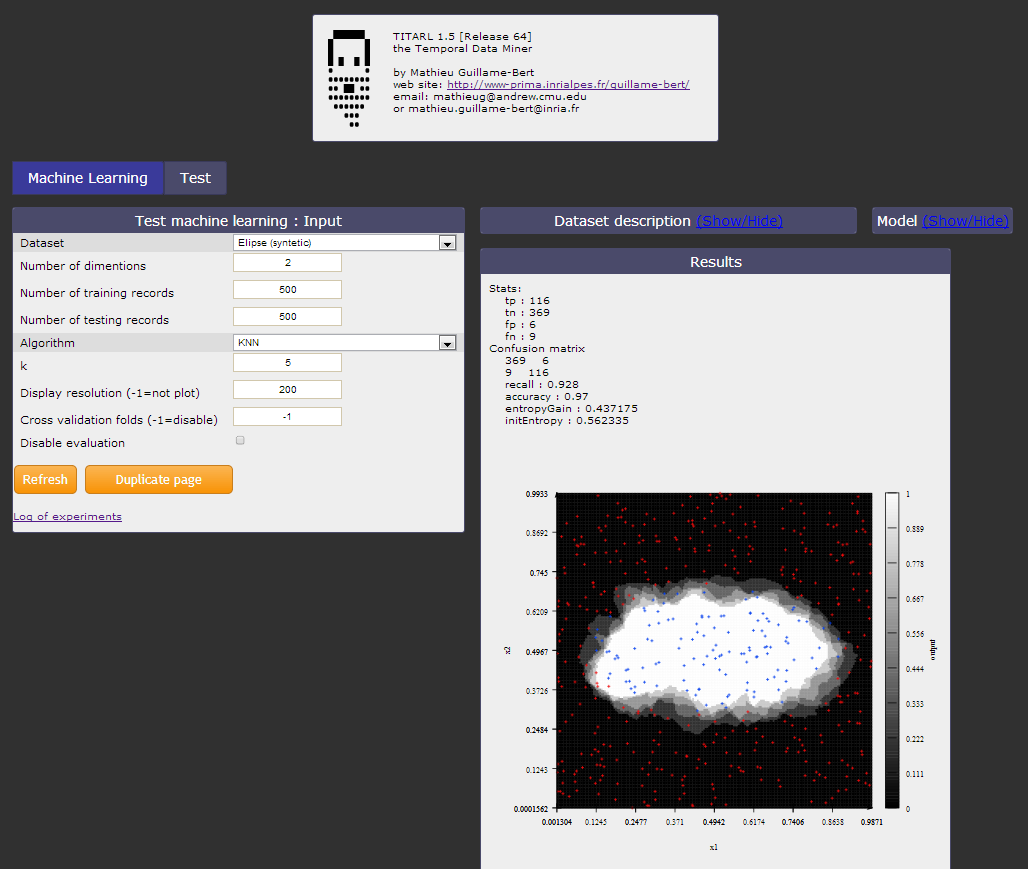
 Download Machine
Learning Lab.
Download Machine
Learning Lab.
Datasets
- The computer generated Database
A syntetic data-set create to test symbolic time sequence data-mining algorithms. - The Home Data Set
The "Home activities dataset" of Tim van Kasteren et al. converted to be imported in TITARL and Event Viewer. - Forex Dataset: Automated Trading Experiment
A three years record of the USD/EUR Forrex market converted to be imported in TITARL and Event Viewer.
Gallery
This sections shows some of the nice pictures that I have generated through my research work. You can click on the picture to get the full size versions.


You can see more of those pictures at the gallery page.
▲ Come back to indexPersonal area
Social ProjectsSee the complete list of projects here.



The core of a robot made of LEGOs
from when I was a kid.

▲ Come back to index
